[DATBASE] DML(SELECT 서브쿼리) + DDL(CREATE/ALTER/DROP)
< 지난 포스팅 정리 >
[DATABASE] DML - SELECT
< 지난시간 정리 > 데이터베이스 => 데이터베이스 관리 시스템 (DBMS) - 대량/분산의 데이터를 효율적으로 관리, 운영하기 위해 사용 (파일시스템의 단점 보완) SQL(Structured Query Language) - DBMS에 데이
thstnqls.tistory.com
DML
select
from
where
group by
having
order by
함수
- 단일행 함수 (문자열 / 날짜 / ifnull)
- 그룹 함수 (통계)
=> 한 개의 테이블 한 개 쿼리를 이용해서 사용
=> 한 개의 테이블에서 두 개이상 쿼리를 함께 적용
SELECT
[서브쿼리]
- 단일행 서브쿼리: 서브쿼리의 결과가 반드시 1행 1열이 나와야 한다.
=, <>(!=),>,<=,<,>=
- 복수행 서브쿼리: 서브쿼리의 결과가 다행 1열이 나와야 한다.
연산자 + in, any, all
< any: 서브쿼리의 리턴값 중 최대값보다 작은
> any: 서브쿼리의 리턴값 중 최소값보다 큰
< all: 서브쿼리의 리턴값 중 최소값보다 작은
> all:서브쿼리의 리턴값 중 최대값보다 큰

* 직책이 manager인 사원들의 급여보다 적은 사원 목록 출력

* 각 부서의 평균 급여보다 적은 사원 목록 출력

* 특수 - 복수열
쿼리 -> 쿼리 ...
ex) scott의 급여보다 큰 급여를 받는 사원에 대한 목록 출력
select ename, sal from where
scott의 급여
> select sal from emp where ename ='scott';
급여보다 큰 급여 사원의 목록
> select empno,ename,sal from emp where sal >=3000;
=> scott의 급여를 확인 후 해당 급여보다 큰 사원의 목록을 따로 출력하면 된다.
합친내용 (서브쿼리)
> select empno,ename,sal from emp where sal>=(select sal from emp where ename ='scott');
* 최고 급여를 받는 사원 목록 출력(empno,ename, sal)

* 'WARD'라는 사원과 급여가 같은 사원 목록 출력
1. ward라는 사원의 급여
2. 해당 급여와 같은사원의 목록
2(1)형태로 쿼리문을 작성할 수 있도록 한다

목록형으로 출력하고 싶으면 where in을 사용하도록 함
* 20번 부서의 사원이 속한 직책과 같은 사원들에 대한 정보
1. 20번 부서의 사원이 속한 직책
2. 해당 직책과 같은 사원들의 정보
Join
두 개 이상의 테이블에서 데이터를 조회
테이블 간의 병합
=> 테이블 곱 = 카테시안 프로덕트
> select *
from emp cross join dept;

> select *
from emp inner join dept;

- equi join = (equal로 연결되었기 때문)
> select *
from emp inner join dept
where emp.deptno = dept.deptno;

* 10번부터 해당하는 사원에 대한 목록
> select *
from emp inner join dept
where emp.deptno = dept.deptno
and emp.deptno =10;

(아래 코드들은 다 같은 내용이다, 형식만 다름)
> select *
from emp inner join dept
on ( emp.deptno = dept.deptno)
where emp.deptno =10;
> select* from emp inner join dept
-> using(deptno)
-> where emp.deptno =10;
(사용하지 말기)
> select empno, ename, deptno, dname
from emp inner join dept
on(emp.deptno=dept.deptno)
where emp.deptno =10;

이렇게 바꿔쓸 수 있다.
> select empno, ename, emp.deptno, dname
from emp inner join dept
on(emp.deptno=dept.deptno)
where emp.deptno =10;
- 테이블 별칭
> select e.empno, e.ename, e.deptno, d.dname
from emp e inner join dept d
on(e.deptno=d.deptno)
where e.deptno =10;
* 직책이 clerk인 사원에 대한 사원번호, 사원이름 , 급여, 부서이름, 부서위치 출력

- nonequi join (부등호)
> select * from emp e inner join salgrade s
on(e.sal>= s.losal and e.sal<=s.hisal);

* 입사년도가 2011년인 사원에 대한 사원번호, 사원이름, 급여, 급여등급을 출력
사원번호, 사원이름, 급여, 급여등급, 부서이름, 부서위치
=> 테이블 3개
> select e.empno, e.ename, e.sal, s.grade, d.dname, d.loc
from emp e inner join dept d
on(e.deptno = d.deptno)
inner join salgrade s
-- on(e.sal>= s.losal and e.sal<=s.hisal);
on (e.sal between s.losal and s.hisal);
같지만 다른 구조로 작성
> select e.empno, e.ename, e.sal, s.grade, d.dname, d.loc
from emp e inner join dept d
inner join salgrade s
on(e.deptno = d.deptno and e.sal between s.losal and s.hisal);

Outer Join
사원이 없는 부서
주문이 없는 상품
left left outer join
right right outer join
- full outer join
* 사원이 없는 부서 출력
> select d.deptno, d.dname, e.empno, e.ename
from emp e right outer join dept d
on e.deptno = d.deptno
where e.empno is null;

self join - 한 테이블 내부에 조인
* 테이블 내부에서 관리자를 확인할 수 있도록 함(자기참조)

//king까지 표시될 수 있도록 함

//king만 뜰 수 있도록 설정

연습문제
서브쿼리
1. BLAKE 보다 급여가 많은 사원들의 사번, 이름, 급여를 검색하시오.
> select empno, ename, sal from emp where sal > any (select sal from emp where ename='BLAKE');

2. MILLER보다 늦게 입사한 사원의 사번, 이름, 입사일을 검색하시오.
> select empno,ename, hiredate from emp where hiredate > any(select hiredate from emp where ename='MILLER');

3. 사원 전체 평균 급여보다 급여가 많은 사원들의 사번, 이름, 급여를 검색하시오.
> select empno, ename, sal from emp where sal > all(select avg(sal) from emp);

4. CLARK와 같은 부서이며, 사번이 7698인 직원의 급여보다 많은 급여를 받는
사원들의 사번, 이름, 급여를 검색하시오.
> select empno, ename, sal from emp where sal > all(select sal from emp where empno=7698)
and (select deptno from emp where ename='CLARK');

5. 부서별 최대 급여를 받는 사원들의 사번, 이름, 부서코드, 급여를 검색하시오.(미해결)
> select empno, ename, deptno, sal from emp where sal in(select max(sal) from emp group by deptno);

조인(join)
1. 부서 테이블과 사원 테이블에서 사번, 사원명, 부서코드, 부서명을 검색하시오. 단, 출력시, 사원명을 기준으로 오름차순으로 정렬하시오.
> select e.empno, e.ename, d.deptno, d.dname from emp e inner join dept d
on (e.deptno=d.deptno)
order by e.ename asc;

2. 부서 테이블과 사원 테이블에서 사번, 사원명, 급여, 부서명을 검색하시오. 단, 급여가 2000 이상인 사원에 대하여 급여를 기준으로 내림차순으로 정렬하시오.
> select e.empno, e.ename, e.sal, d.dname from emp e inner join dept d
on( e.deptno = d.deptno)
where e.sal>=2000 order by e.sal desc;

3. 부서 테이블과 사원 테이블에서 사번, 사원명, 업무, 급여, 부서명을 검색하시오. 단, 업무가 MANAGER이며 급여가 2500 이상인 사원에 대하여 사번을 기준으로 오름차순으로 정렬하시오.
> select e.empno, e.ename, e.sal, d.dname from emp e inner join dept d
on( e.deptno = d.deptno)
where e.job='MANAGER' and e.sal >=2500 order by e.empno asc;

데이터 입력
1. 데이터베이스 - 폴더
2. 테이블
DDL
create - 생성
alter - 수정
drop - 삭제
CREATE - 생성 / DROP - 삭제
데이터베이스
create database 데이터베이스명;
수정
drop database 데이터베이스명;
데이터베이스(test2) 생성/삭제 옵션 명령어 (에러출력되지 않음)
> create database if not exists test2;
> drop database if exists test2;
[테이블 생성]
테이블 - 열(데이터 규정)을 포함
테이블명, 컬럼명 - 식별자규칙(소문자)
create table 테이블(
컬럼명 데이터타입(크기) 옵션,
컬럼명 데이터타입(크기) 옵션,
..
);
데이터타입
https://mariadb.com/kb/ko/data-types/
Data Types
mariadb.com
문자열
- char(고정형) 7=>4 -3(남김) - 검색성능 뛰어남
- varchar(가변형) 7=>4 -3(제거) - 공간 효율
- 큰 데이터
tinytext / text / mediumtext / longtext
숫자형
- 정수 : tinyint, smallint, mediumint, int, bigint
- 실수 : decimal(->number), float, double
- decimal(정수자리수, 소수점아래자리수)
*보통 정수에는 int 실수에는 decimal을 많이 쓴다.
날짜형
- date / datetime / time
바이너리
- 이미지 / 파일
* test1에 dept테이블 만들기
> create table dept(
deptno int(2),
dname varchar(14),
loc varchar(13)
);
* 기존에 있는 테이블을 참조하여 새로운 형태의 테이블로 생성(1)
> create table emp_year1
-> as select empno, ename, sal, sal*12+ifnull(comm,0) from sample.emp;

* 기존에 있는 테이블을 참조하여 새로운 형태의 테이블로 생성(2)
> create table emp_year2
-> as select empno,ename,sal,sal*12+ifnull(comm,0)annsal from sample.emp;

* 기존에 있는 테이블을 참조하여 새로운 형태의 테이블로 생성(3)
> create table emp_year3
as select empno no, ename name, sal , sal*12 + ifnull(comm,0) annsal, hiredate hdate from sample.emp
where deptno= 30;

* 데이터 없이 테이블의 골격만 참조하여 만들고 싶을 때
> create table empty_dept1
-> as select*from sample.dept
-> where 1 !=1;
다른 명령어로는...
> create table empty_dept2 like sample.dept;

ALTER - 테이블 수정
- 열 정의를 수정
열 생성, 수정, 삭제
alter table 테이블 옵션 ...
* 테이블에 새로운 컬럼 추가
> alter table emp_alter
-> add job varchar(9);

* 기존 컬럼 데이터타입 초기용량 변경
> alter table emp_alter
-> modify job varchar(20);

=> modify의 조건 : size가 커지는 방향으로 수정해야함 (나중에 저장된 데이터 중 size를 줄이면 잘리는 현상 발생)
* 컬럼 이름 변경하기
> alter table emp_alter
-> rename column job to work;

* 컬럼 삭제하기
> alter table emp_alter
-> drop work;

* 테이블 이름 변경
> alter table emp_alter rename emp_alter2;

* 테이블 삭제
> drop table 테이블명;
DML
select
insert update delete
INSERT - 데이터의 추가
insert into 테이블 명 values(값1, 값2, 값3...);
1. 값의 순서는 컬럼의 순서와 동일
2. 문자열 값 -> '값'

* 테이블에 데이터 삽입
> insert into dept1 values(10,개발부, '서울');

> insert into 테이블명(컬럼명, 컬럼명 ..) values(값1,값2,값3...);
* 컬럼명 순서와 갯수가 값의 순서와 갯수와 동일
* 컬럼을 지정한 순서에 맞춰 데이터 삽입하기

* 연속적으로 데이터를 입력해도 상관없음
=> insert into 테이블명 values(값1,값2,값3...),(값1,값2,값3...),(값1,값2,값3...);
* 테이블 생성 (데이터 없음) -> 데이터 추가 -> 확인
> create table dept2 as select * from sample.dept where 1 !=1;
> insert into dept2 select * from sample.dept;
> select * from dept2;

NULL -> no : 값이 무조건 있어야 함
-> yes : 비어있어도 insert됨 (비워진 내용의 insert된 내용의 디폴트 값은 null이다.)

> insert into dept1 values(30,null,null);
==> 해당 방식을 사용할 때는 삽입 내용의 개수를 맞춰 넣어야 한다. (넣을 정보가 없고 null이 가능하면 해당란에 null작성)
* null 설정 값 조절
> create table dept3 (
-> deptno int(2) not null,
-> dname varchar(14) not null,
-> loc varchar(13));

* default값 생성
> create table dept1(
-> deptno int(2) default 90,
-> dname varchar(14),
-> loc varchar(13));
* 데이터 삽입
> insert into dept1 values(default,'개발부','서울');

UPDATE - 수정
> update 테이블명 set 컬럼명 = 값, 컬럼명 = 값, 컬럼명 = 값
일부 행만 영향
> update 테이블명 set 컬럼명 = 값, 컬럼명 = 값, 컬럼명 = 값 where 조건
* 직책 바꾸기
> update emp1 set job ='CLERK';

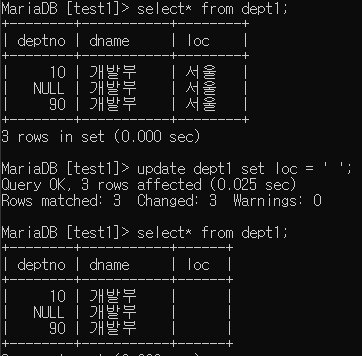
열 단위의 데이터를 삭제할 때는 update문을 사용하여 공백 또는 null을 넣도록 한다.
> update dept1 set loc = ' ';
DELETE - 삭제
전체 행 삭제
delete from 테이블명;
특정행 삭제
delete from 테이블명 where 조건;
* deptno가 30인 부서 삭제
> delete from emp1 where deptno =30;
